Faster ordered maps for Java
Sorted maps are useful alternatives to standard unordered hashmaps. Not only do they tend to make your programs more deterministic, they also make some kinds of queries very efficient. For example, one thing we frequently want to do at work is find the most recent observation of a sparse timeseries as of a particular time. If the series is represented as an ordered mapping from time to value, then this this question is easily answered in log time by a bisection on the mapping.
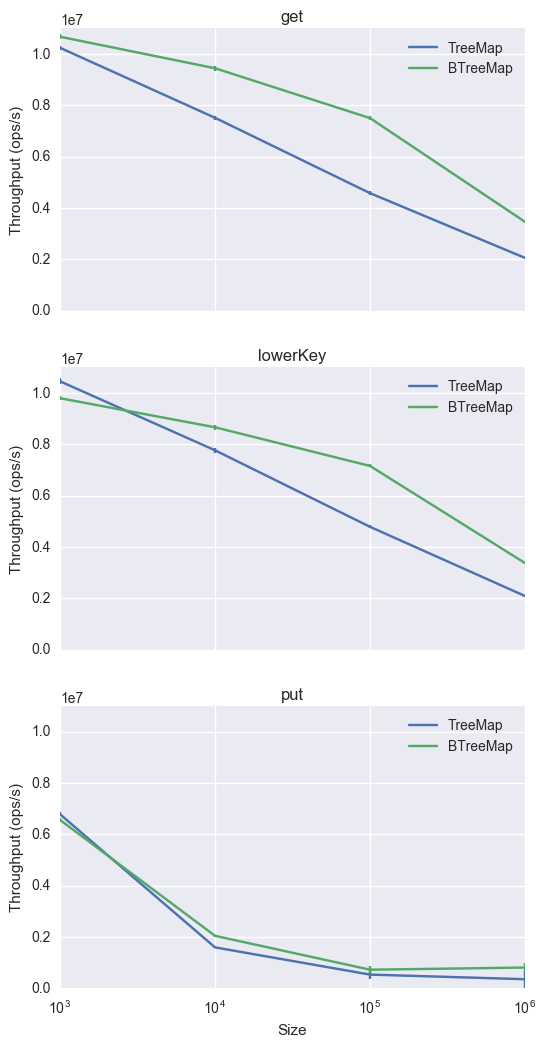
A disadvantage to using ordered maps is that they tend to have higher constant factors than simple unordered ones. Java is no exception to this rule: as we will see below, the standard HashMap outperforms the ordered TreeMap equivalent by two or three times.
My new open source Java library, btreemap, is an attempt to ameliorate these constant factors. As the name suggests, it is based on B-tree technology rather than the red-black trees that are used in TreeMap. These “mechanically sympathetic” balanced tree data structures improve cache locality by using tree nodes with high fanout.
My library offers both boxed (BTreeMap) and type-specialized (e.g. IntIntBTreeMap) unboxed variants of the core data structure. Benchmarking it against some competing sorted collections (including fastutil and MapDB 1) reveals it beats them by a good margin, though it still carries a performance penalty versus the simple HashMap:

So switching from TreeMap to IntIntBTreeMap may be worth a 2x performance increase. Nice!
These benchmarks:
- Use JMH to ensure e.g. that the JVM is warmed up
- Were run on an
inttointmap with 100k keys - Do not include
lowerKeynumbers for HashMap or Int2IntRBTreeMap, which do not support the operation - Are in memory-only and do not make use of the persistence features of MapDB
Performance benefits depend on the amount of data you are working with. Small working sets may fit into level 1 or 2 cache so will pay a relatively small penalty for a lack of cache locality. These graph show how throughput depends on the number of keys there are in the working set, where keys are distributed between a varying number of fixed size (100 key) maps. B-trees do not start to show a performance advantage until we reach 10k keys or so:
There are a few interesting things about the implementation:
-
The obvious way to represent a tree node is as an object with two fields: a fixed size array of children, and a size (number of children that are present). However, in Java this means taking two indirections when you want to access a child (you need to first load the address of the array from the object, then load the child at an offset from that base address). Instead, I define tree nodes as a class with one field for each possible child, and then use sun.misc.Unsafe for fast random access to these fields. This change made
getabout 10% faster in my testing. -
The internal nodes store the links to their children in sorted order. Therefore, you’d expect binary search to be a good way to find the child associated with a particular tree. In practice I found that linear search was 20% or more faster, probably due to branch prediction improvements.
-
To avoid copy-pasting the code for each unboxed version of the data structure, I had to come up with a horrible templating language partly based on JTwig. Value types can’t come fast enough!